Entropy
정보이론에서 Entropy는 어떤 확률 p를 가진 정보를 전송하는 데에 필요한 비트 수의 평균값입니다. 예를 들어 동전을 던졌는데 앞면이 나왔는지, 뒷면이 나왔는지를 상대방에게 알려주려고 합니다. 2가지의 경우밖에 존재하지 않음으로 1bit (0, 1)로 나타낼 수 있습니다. 두 경우의 확률 값이 0.5 임으로 0.5*1 + 0.5*1 = 1로 엔트로피는 1입니다. 그런데 이는 동전의 앞면과 뒷면이 나올 확률이 둘 다 1/2이라는 가정하에 일어나는 일입니다. 만약 던졌을 때 앞면만 나오는 동전이 있다면 불확실성은 존재하지 않습니다. 이 경우 엔트로피는 0입니다. 엔트로피는 문제의 복잡도를 측정하는 척도이며, 클수록 불확실성이 높으며 문제가 복잡합니다.
엔트로피는 아래와 같이 정의됩니다.
$$
H(S) = -\sum_{s \in S}P(s)log_2P(s)
$$
앞선 동전 던지기의 예제에서 앞면과 뒷면이 나올 확률이 1/2로 동일한 경우 엔트로피의 계산은 다음과 같습니다.
$$
H(S) = -(0.5 * log_2(0.5) + 0.5 * log_2(0.5)) = 1
$$
던졌을 때 무조건 앞면만 나오는 동전의 엔트로피는 다음과 같습니다.
$$
H(S) = -(1 * log2(1) + 0 * log_2(0)) = 0
$$
위 식으로 앞면이 나올 모든 확률 값에 대한 entropy를 계산하면 아래와 같습니다.
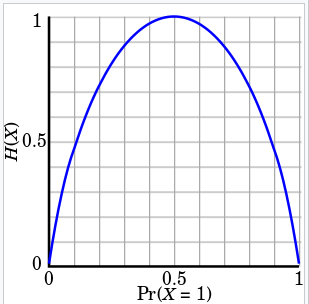
앞면이 나올 확률이 0.5일 떄 가장 엔트로피가 높은 것을 볼 수 있습니다.
우리가 Decision Tree로 테니스를 칠지 치지 않을지 분류하고자 한다고 합시다. 만약 어떤 노드에서 "테니스를 친다"가 9개, "치지 않는다"가 5개가 있다고 하면, 이 노드에서 테니스를 칠지 여부를 기준으로 한 Entropy는 아래와 같이 계산할 수 있습니다.
$$
H(S) = -\frac{9}{14}log_2(\frac{9}{14}) -\frac{5}{14}log_2(\frac{5}{14}) \approx0.940
$$
Information Gain
특정 정보를 활용하여 분류하기 이전 엔트로피가 1이었는데, 분류 이후 엔트로피의 가중합이 0.8 이라면 Information Gain 은 0.2입니다. 불확실성, 즉 Entropy가 줄어들었으므로 분류하기 이전보다 더 값들이 나누어져 있음을 뜻합니다. Information Gain은 아래와 같이 구할 수 있습니다.
$$
Gain(S,A) = H(S) - \sum_{v \in Value(A)} \frac{|S_v|}{|S|}H(S_v)
$$
Decision Tree
Decision tree (결정트리)는 매 노드에서 특정 feature를 이용하여 분기를 나눔으로 데이터를 구분합니다. 자동차, 오토바이, 자전거를 구분한다고 합시다. 엔진이 있는지로 데이터를 먼저 구분할 수 있습니다. 엔진이 있는지로 먼저 구분하였다면 엔진이 존재하지 않는 자전거는 바로 구분할 수 있을 것입니다. 엔진이 존재하는 것들은 자동차, 오토바이가 있습니다. 이제, 이들 중 바퀴의 개수로 이들을 구분합니다. 바퀴가 4개인 경우 자동차, 그렇지 않은 경우 오토바이로 구분합니다. 이 과정을 트리구조로 그리면 아래와 같은 그림이 나옵니다.
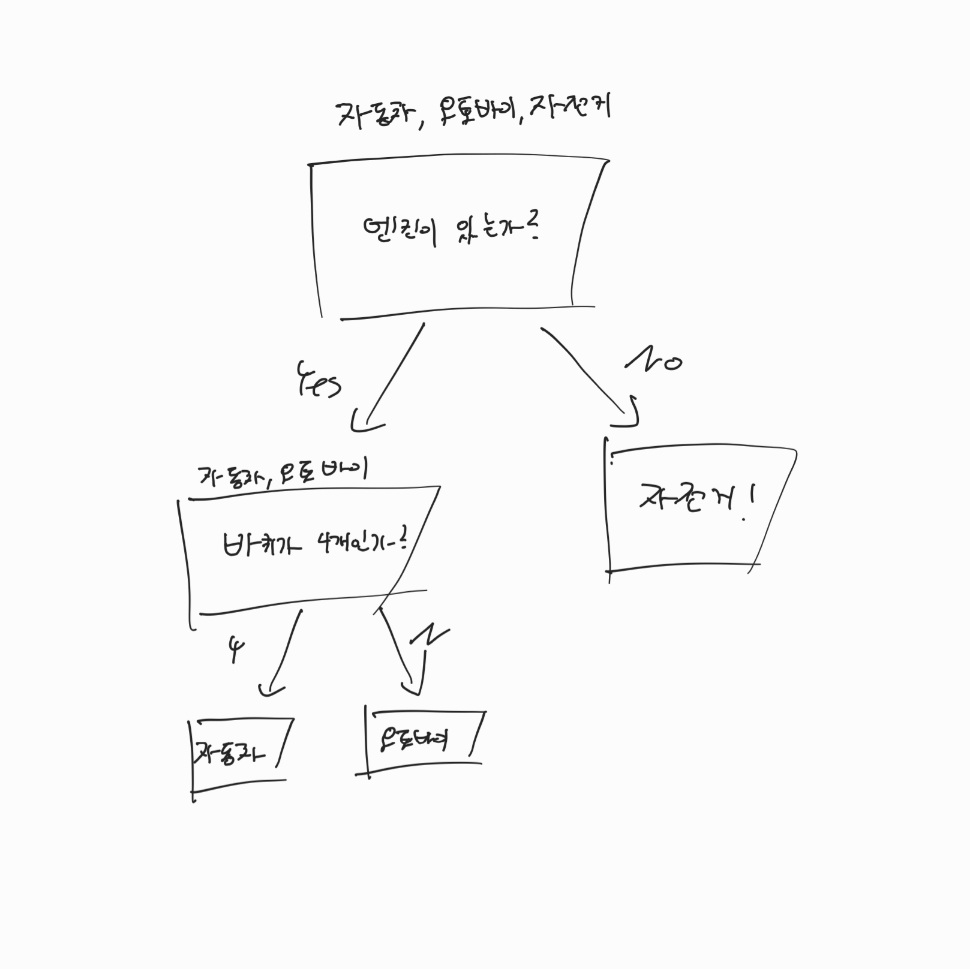
Decision Tree의 구조

Decision Tree는 Tree의 구조를 하고 있습니다.
- Root node : 최상단 노드
- Intermediate Node : 최상단 노드가 아니면서 자식이 존재하는 노드
- Terminal Node : 자식이 존재하지 않는 노드
Root node와 Intermediate Node를 거쳐 Terminal Node로 도착하면, 데이터는 Terminal Node가 나타내는 값으로 분류됩니다.
Decision Tree의 학습 (ID3)
아래와 같은 데이터가 존재합니다. 우리는 다른 정보들로부터 그날 PlayTennis의 여부를 결정하고자 합니다. Root Node에서는 아직 분류가 진행되지 않았습니다. PlayTennis 가 Yes와 No인 경우가 각각 9, 5개임으로 Root Node에서의 엔트로피는 약 0.940입니다. 이제 우리는 특정 feature를 기준으로 분기를 나누어야 하는데, 이때 Information Gain이 가장 크게 나눌 수 있는 feature를 구합니다. Outlook, Temperature, Humidity, Wind로 분기하였을 때 각각의 Information Gain을 계산한 후 Information Gain이 가장 큰 값으로 분기하도록 결정합니다.
| Day | Outlook | Temperature | Humidity | Wind | PlayTennis |
|---|---|---|---|---|---|
| 1 | Sunny | Hot | High | Weak | No |
| 2 | Sunny | Hot | High | Strong | No |
| 3 | Overcast | Hot | High | Weak | Yes |
| 4 | Rain | Mild | High | Weak | Yes |
| 5 | Rain | Cool | Normal | Weak | Yes |
| 6 | Rain | Cool | Normal | Strong | No |
| 7 | Overcast | Cool | Normal | Strong | Yes |
| 8 | Sunny | Mild | High | Weak | No |
| 9 | Sunny | Cool | Normal | Weak | Yes |
| 10 | Rain | Mild | Normal | Weak | Yes |
| 11 | Sunny | Mild | Normal | Strong | Yes |
| 12 | Overcast | Mild | High | Strong | Yes |
| 13 | Overcast | Hot | Normal | Weak | Yes |
| 14 | Rain | Mild | High | Strong | No |
Wind를 선택하였을 때의 Information Gain을 구해봅시다. Wind 값 별로 PlayTennis 값을 세면 다음과 같습니다.
| Wind | PlayTennis | Count |
|---|---|---|
| Weak | Yes | 6 |
| Weak | No | 2 |
| Strong | Yes | 3 |
| Strong | No | 3 |
$$
\begin{align*} Gain(S,Wind) &= H(S) - \frac{|S_{Weak}|}{|S|}H(S_{Weak}) - \frac{|S_{Strong}|}{|S|}H(S_{Strong}) \\ &= 0.940 - \frac{8}{14} 0.811 - \frac{6}{14}\ {1.00} \\ &= 0.048 \end{align*}
$$
여기서 H(S_Weak)의 값은 Wind 값이 Weak인 데이터만 모아서 따로 엔트로피를 계산한 값입니다. H(S_Strong)의 경우도 마찬가지입니다.
같은 원리로 다른 feature 들에 대해 Information Gain을 구하면 Temperature는 0.029, Humidity는 0.151, Outlook은 0.246의 값을 얻을 수 있습니다. 따라서 Decision Tree는 Information Gain이 가장 큰 Outlook을 사용하여 분류합니다.
만약 분류한 후 생긴 노드가 Terminal node가 아닌 Intermediate Node라면 그 Intermediate Node에서 위 과정을 반복해주어야 합니다. 이 과정을 반복하면 아래와 같은 Decision Tree를 얻을 수 있습니다.

이렇게 Information Gain을 이용하여 Decision Tree를 학습하는 알고리즘을 ID3 알고리즘이라 합니다.
'Study > ML, DL' 카테고리의 다른 글
| Metrics - Accuracy, Precision, Recall and F1-Score (0) | 2022.10.02 |
|---|
댓글